Current Research Projects
Human Activity Recognition and Rehabilitation Exercise Evaluation
This ICT Division and IUB funded project intends to develop machine learning-based approaches which can be used for the recognition of various activities using data from wearable sensors (e.g. accelerometer, gyroscope) and motion sensing devices (e.g. kinect). In addition, we intend to develop models which could be used by people seeking rehabilitation support at the CRP. Particularly, our research intention is to record movement data while the rehabilitation exercises are performed. In addition to sensor data, the plan includes collection of visual data of the patient performing exercises using 3D sensors. Finally, we intend to use time series data analysis to learn the activity, measure (or grade) the performance of the patient, level of improvement, identify the areas and time when the patient is facing difficulty. In order to achieve automatic or semi-automatic activity recognition and exercise evaluation, we have designed self attention and graph convolution based architectures. The works on self-attention based architectures for activity recognition from sensor data have been published in ECAI 2020 and PAKDD 2021.
Traffic Forecasting Using Graph Convolutional Network

Intelligent Transportation System (ITS) is being developed
in many countries around the world and traffic forecasting
lies in the heart of ITS. Traffic intensity is determined by
the average speed of vehicles passing through observed road
junctions in a traffic network at each time interval and the
goal of traffic forecasting is to predict the traffic
intensity in near future by observing the traffic data from
the past and current time along with the physical traffic
network. Research in deep learning models to forecast
traffic intensities has gained great attention in recent
years due to their capability to capture the complex
spatio-temporal relationships within the traffic data.
However, the task of traffic forecasting is challenging
because there lies a complex spatio-temporal relationship in
traffic data as the traffic within a busy city changes
heavily in different locations throughout different periods
in a day. As the traffic junctions and roads between them
can be considered as a graph, we employ graph neural
networks to model the traffic forecasting problem which have
been published in IJCNN 2021 and PAKDD 2021. Also, to
capture the repetitive traffic pattern we consider the
traffic data of the past few days instead of considering the
traffic data of the past day only. With rigorous experiments
we have produced better results for accurate traffic
forecasting.
Geospatial Analysis Using Satellite Images
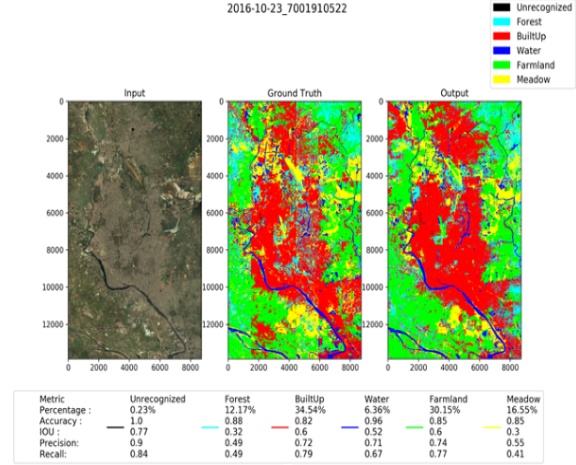
Under this project we have completed 3 tasks; namely, (a) Land Use Land Cover (LULC), (b) Google earth engine based indices generation, (c) urban buildup classification. Generally, Land use land cover (LULC) is defined how the land is used by humans or what the surface is covered with. Specifically, land use means how a particular land is being used for; for example, farmland, built-up etc. Land Cover refers to what the surface is covered with; it can be river, forest, mountains etc. Thus, LULC information and LULC change over a period of time obtained from satellite data can be used to analyze the geography, socio-economic condition, poverty estimation, urban planning, building categorization etc. Deep learning based methods are extensively effective on satellite images for automatic analyses towards above mentioned applications . However, the prelude for applying the deep learning methods on satellite images is to have a good amount of images annotated with ground-truth LULC classes. Most importantly, pixel by pixel LULC class annotation on the satellite images is the utmost necessity to apply deep learning methods so that we can effectively use the methods for above mentioned applications. Hence, the goal of this project is to produce good quality LULC annotation data pixel by pixel for Dhaka so that deep learning models can be trained effectively. With a sufficiently trained model, we can employ state of the art segmentation models to perform LULC over the entire Bangladesh without any human effort. Moreover, this project targets to develop novel segmentation models that can outperform the existing ones by significant margin. Urban buildup classification work is done in collaboration with Dr. Moinul Islam Zaber, Dr Shibasaki Ryosuke and Center for Spatial Information Science, University of Tokyo.
Understanding The Transcriptomic Responses to Environmental Change in Hilsa

In order to gain an in-depth understanding of the change in Hilsa migration, adaptation and reproduction emanating from climate change an integrated omics (genomics, transcriptomics, proteomics, metabolomics and metagenomics) approach has to be adopted. Use and development of different bioinformatics algorithms, tools, and scripts as well as high-performance computing facilities are required to analyze these omics datasets. Moreover, GIS and Remote sensing technologies are required to identify deep sea habitats and collect samples. Here at AGenCy lab IUB, we made connections with the group, led by Professor Haseena Khan, who were responsible for first sequencing of Hilsa. In this project, we will work in direct collaboration with this group. Professor Haseena Khan and her team will lead the sample collection, quality control and sequence data generation and analysis. We at IUB, in collaboration with Dr. A Baten from AgResearch, NZ and Professor M Shoyaib from IIT, DU will lead the computational analysis of the data extracted. In this project we aim to focus on the first phase of the integrated omics approach
Image Generation Using Variational Autoencoders and Energy Based Models

Machine learning practitioners have long sought generative models that can accurately estimate the underlying data distribution and are able to produce diverse and semantically meaningful image samples. In this project, we take part in a similar quest. Our research directions include (but not limited to) developing improved variational inference techniques, coming up with more efficient methods to train energy based models and better traversing the latent space with Riemannian geometry and manifold assumption.
Predicting Association Between Entities in Heterogeneous Biological Networks
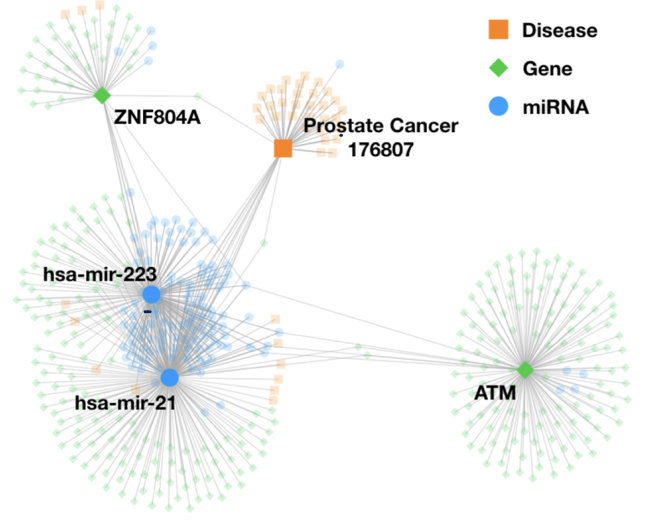
Heterogeneity is inherent in biological networks which consist of different entities as nodes (i.e., genes, diseases, drugs, function) and represent the relationships between these entities as edges. Predicting potential associations between biological entities currently has been an important problem in biomedical research. In general, a deep learning model uses the contextual information and structures of the heterogeneous networks to identify the associations. This project will utilize powerful tools, e.g., GNN & MRF, to develop a more accurate, explainable model for link predictions in heterogeneous networks. Dr. Azad Abul Kalam will collaborate with us on this project.
Identifying Habitable Planets From 21 CM Telescope Data Using Machine Learning

Modern astronomers together with engineers have built large array of radio telescopes to look for faint signals generated billions of years back buried in big chaotic datasets, like a needle in a haystack. The contributors of noise in those signals range from humans to all celestial events happening in the path the signal is traveling. To be able to extract a signal successfully, they need to first simulate the complete pipeline of an observation so that each element within the pipeline can be understood and taken care of separately. It used to be dose based on some predefined models developed by astrophysicists, however in recent times the amount and scope of data accumulated by these telescopes have increased exponentially in amount. In this project we intend to develop or modify existing techniques of noise removal in radio telescope signals, specially 21-cm signals using various machine learning and deep learning techniques. This project is collaborated with South African Radio Astronomy Observatory and Low Frequency Array (LOFAR) telescope.
Machine Learning In Particle Physics
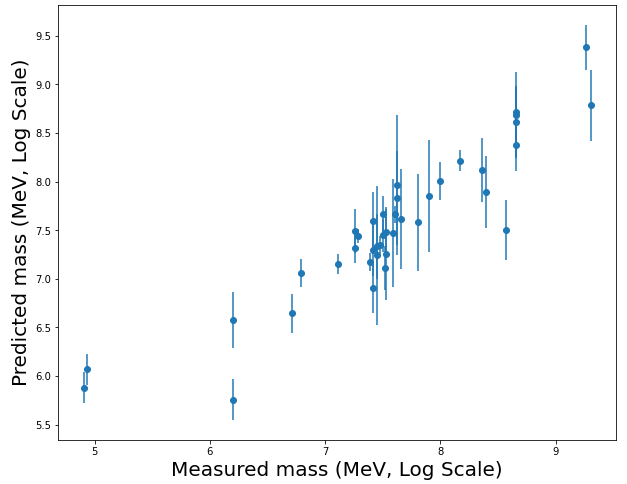
Quantum chromodynamics (QCD) is the theory of the Strong interaction. In QCD, massive fermionic particles (quarks and antiquarks) interact via the exchange of massless bosons (gluons). The fundamental particles of QCD, quarks and gluons, carry colour charge and form colourless bound states at low energies, of which mesons and baryons are subjects of interest From knowledge of the meson spectrum, we use Neural Networks and Gaussian Processes to predict the masses of baryons. These results compare favourably to the Constituent Quark Model.
From here on, interesting research avenues can be pursued, such as the existence and predictions of the existence of glueballs, and the masses of pentaquarks and other exotic hadrons.
Bangla Natural Language Processing
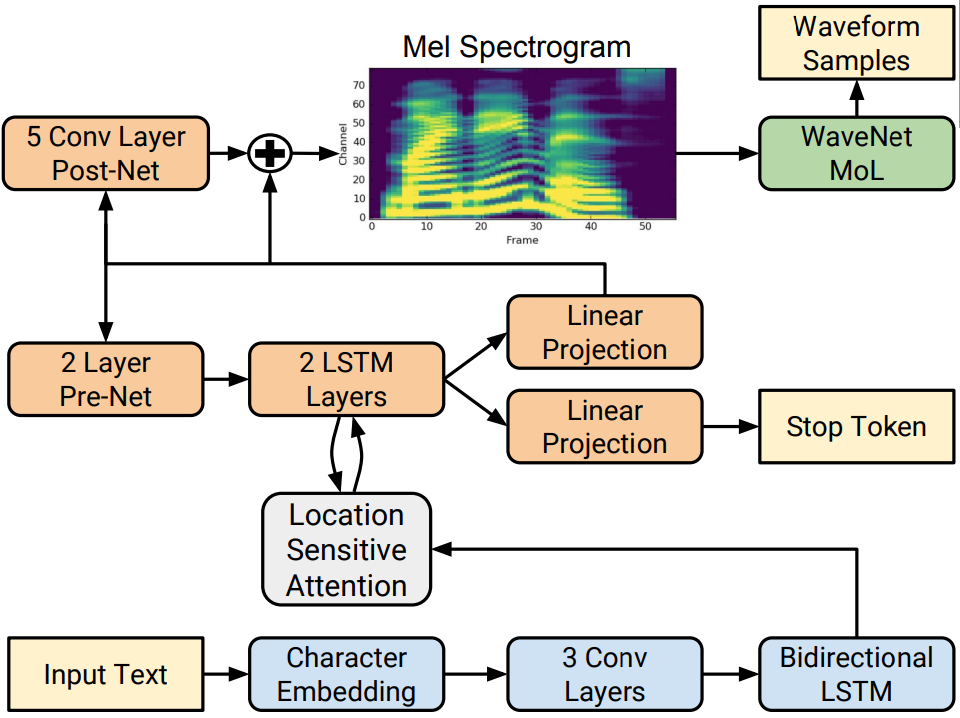
In this project, we intend to build a speaker independent Text-to-Speech (TTS) system in Bangla language. To solve the task, we will utilize the SOTA TTS model, Tacotron 2. This model is a combination of two neural network architectures: a modified Tacotron 2 model which is a recurrent sequence-to-sequence model with attention that generates mel-spectrograms from input text. And, a flow-based neural network model named WaveGlow. In this regard, we have created a multi-speaker TTS dataset for Bangladesh Bengali (bn-BD) and Indian Bengali (bn-IN) from Open Speech and Language Resources (OpenSLR) dataset. In our initial experiment, we are interested in the bn-BD dataset. It has audio data of 6 different speakers and corresponding text. Dr. Md Iftekhar Tanveer and Dr. Syeda Sakira Hassan are collaborating with us in this project.
Deep Learning On Graph Data
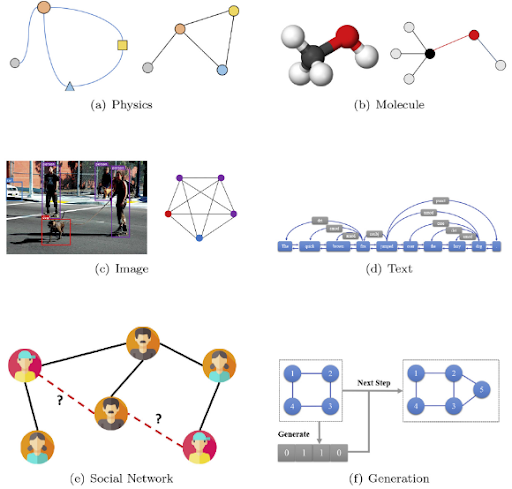
Nowadays, Graph Representation Learning has seen
incredible success across a wide range of modern
applications such as recommendation systems, drug discovery,
computer vision, particle physics, combinatorial
optimization, human activity recognition, etc. In general, a
graph consists of nodes and edges where edges depict the
relationship between nodes. For instance, the users are
nodes in a social network, and edges represent their
friendship/interactions. In brief, Graph Neural Networks
(GNNs) are designed to compute the low dimensional
meaningful embeddings for nodes/graphs through utilizing the
structural information and node attributes (if available).
These latent representations are used in different
downstream tasks e.g., node classification, graph
classification, link prediction, community
detection/clustering, etc. The high-impact applications of
GNNs are leading the research towards developing more
advanced deep learning methods. In the high-level view, we
aim to leverage probabilistic graphical models,
self-supervision learning, contrastive learning, tensor
decomposition, and Bayesian modeling into developing more
robust, interpretable, and explainable GNNs.
Past Research Projects
A Comparative Study On Disaster Detection From Social Media Images Using Deep Learning

The primary objective of this ICT Division, Bangladesh project is to create an annotated database containing images or videos of different types of disasters. Once the database is created this data will be used to train a deep learning module that will be able to identify what disaster is happening given an image. We intend to also improve further finetune the classification to detect the degree of severity of a disaster. Intended final product is to build a system for the ministry of Disaster management and relief that will be able to inform appropriate authority the location, type and severity of a disaster.
Bangla Word Embedding Evaluation
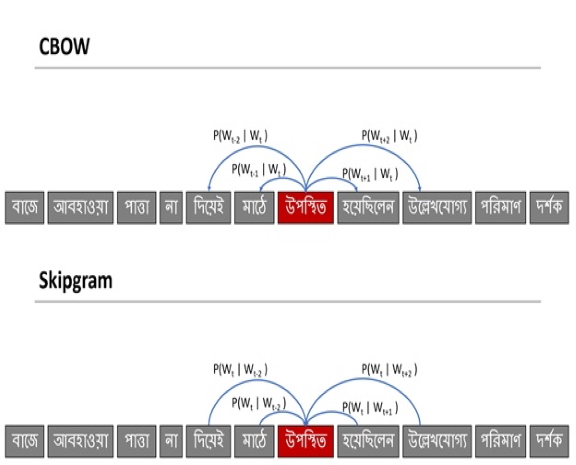
This IUB funded project aims to create a Bangla language corpus. Currently there are 700,000 articles are included in this corpus and increasing. Based on this corpus we are working improving bangle word embedding issue. This word embedding are vector representations of word that allow machines to learn semantic and syntactic meanings by performing computations on them. Two well known embedding models are CBOW and Skipgram. Different methods proposed to evaluate the quality of embedding are categorized into extrinsic and intrinsic evaluation methods. This research will focuses on intrinsic evaluation of the evaluation of the models on tasks, such as analogy prediction, semantic relatedness, synonym detection, antonym detection and concept categorization.
Medical Pill Image And Video Dataset Creation
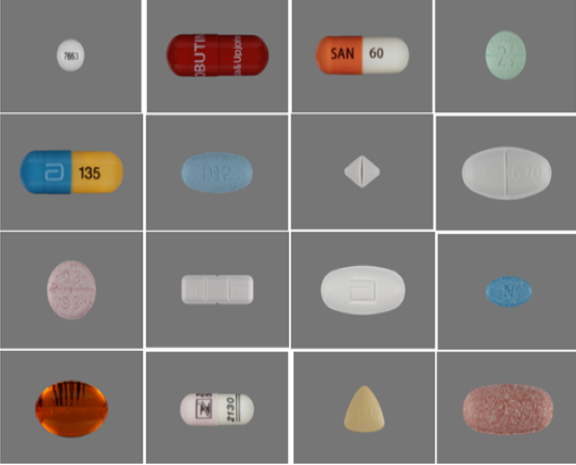
This ICT Division, Bangladesh funded project focuses on creating an annotated database of images and videos of all medicine available in Bangladesh. After the database is available a deep learning model will be used to detect pills in an images or video. Ones the pill is detected next task is to identify the pill using deep learning and computer vision techniques. Based on this understanding a mobile application will be created that will be able to confirm visually impared individuals or elderly patients with short-term memory loss what medicine they are taking.
Video Captioning
While describing spatio-temporal events in natural language, video captioning models mostly rely on the encoder’s latent visual representation. Recent progress on the encoder-decoder model attends encoder features mainly in linear interaction with the decoder. However, growing model complexity for visual data encourages more explicit feature interaction for fine-grained information, which is currently absent in the video captioning domain. Moreover, feature aggregations methods have been used to unveil richer visual representation, either by the concatenation or using a linear layer. Though feature sets for a video semantically overlap to some extent, these approaches result in objective mismatch and feature redundancy. In addition, diversity in captions is a fundamental component of expressing one event from several meaningful perspectives, currently missing in the temporal, i.e., video captioning domain. To this end, we propose Variational Stacked Local Attention Network (VSLAN), which exploits low-rank bilinear pooling for self-attentive feature interaction and stacking multiple video feature streams in a discount fashion. Each feature stack’s learned attributes contribute to our proposed diversity encoding module, followed by the decoding query stage to facilitate end-to-end diverse and natural captions without any explicit supervision on attributes. We evaluate VSLAN on MSVD and MSR-VTT datasets in terms of syntax and diversity. The CIDEr score of VSLAoutperforms current off-the-shelf methods by 7.8% on MSVD and 4.5% on MSR-VTT, respectively. On the same datasets, VSLAN achieves competitive results in caption diversity metrics.
Realtime Air Quality Monitoring And Pollution Modeling From IOT Device

This ICT Division, Bangladesh, funded project intends to deploy 100+ inhouse IoT air quality monitoring devices in five different locations of dhaka city to record the level of PM2.5, CO, CO2, flammable gas. Based on the data collected an air pollution model will be developed for the Department of Environment of People's republic of Bangladesh Government. The objective of the system is to provide real time dynamic visualization of pollution trends and forecasting. Moreover, the model should also be able to identify sources and causes of pollution. This project is collaborated with Department of Environment Bangladesh government.
Deciphering Of Bio-Electrochemical Activities Generated During Argon Plasma Jet Deformation Of Bacteria Cell Morphology Using Machine Learning
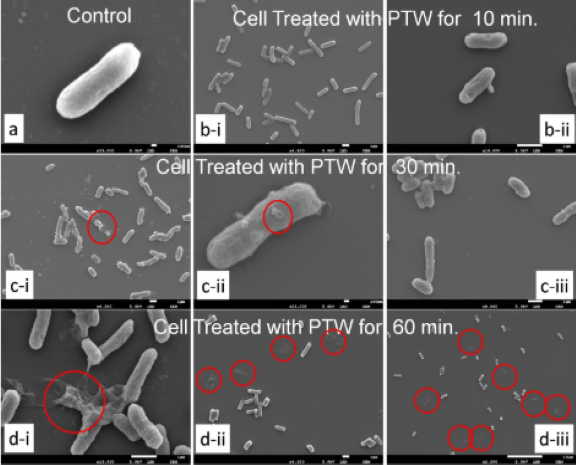
This project utilizes and explores the potential use of machine learning techniques to predict the activities during an experiment of bacterial-cell inactivation using argon-plasma-jet. Our experiments have confirmed that argon-plasma-jet can be used for bacterial cell deformation or killing microorganisms. A targeted high-energy low-temperature argon-plasma-jet is projected on microorganisms and it completely destroys those organisms. There are more than 250 known and unknown chemical reactions occuring during that process depending on different operating conditions. Beside these, high local-electric-field and photons coming out from the jet front also active at the same time. Experimentally, it is quite impossible to track the synergic effect of plasma species and the jets electric field on the cell. This proposed work is the initial step to understand and predict this bio-electrochemical process through computer simulation, to have a better control on the jet-surface interaction process, and its further application. We will do the electro dynamic modelling of the plasma jet using differential machine learning modeling technique. This project is collaborated with Kanazawa university Japan.
High Speed Detection Of Optical Disc In Retinal Fundus Image
The first task in any retinal fundus image processing is to detect the optical disk, as this is the prime location in a fundus image from where all the retinal blood vessels originate. In this paper, a faster method to detect retinal optical disk is proposed that uses mean intensity value of retinal image to detect the center of optical disc, which can be used in retinal image based person authentication system or retinal disease diagnosis. A candidate based approach on the green channel of an RGB fundus image is used to detect optical disc center location. The system has been successfully tested on several publicly available standard databases, namely: DRIVE, MESSIDOR, VARIA, VICAVR and DIARETDB_01 and produced 97.5%, 97.8%, 94%, 93.1% and 86.5% accuracies respectively. It is observed that, if lower recognition accuracy is accepted (from 100% to 97.5%) on DRIVE database, the detection speed increases from 7 seconds to 2 seconds per image, which is faster than any other previous methods with such high accuracies.
Dermatological Disease Diagnosis Using Color Skin Images
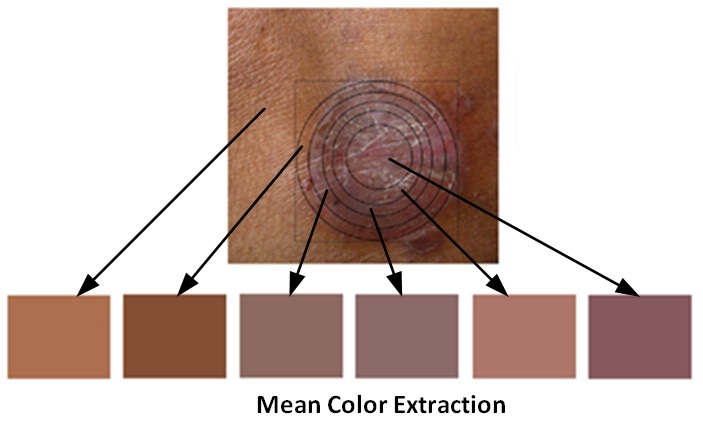
This project is a machine intervention in medical diagnostics. Etymologically, dermatology is the medical discipline of analysis and treatment of skin anomalies. The system presented is a machine intervention in contrast to human arbitration into the conventional medical personnel based ideology of dermatological diagnosis. The system works on two dependent steps - the first detects skin anomalies and the latter identifies the diseases. The system operates on visual input i.e. high resolution color images and patient history. In terms of machine intervention, the system uses color image processing techniques, k-means clustering and color gradient techniques to identify the diseased skin. For disease classification, the system resorts to feedforward backpropagation artificial neural networks. The system exhibits a diseased skin detection accuracy of 95.99% and disease identification accuracy of 94.016% while tested for a total of 2055 diseased areas in 704 skin images for 6 diseases.
Age Group Recognition From Facial Image
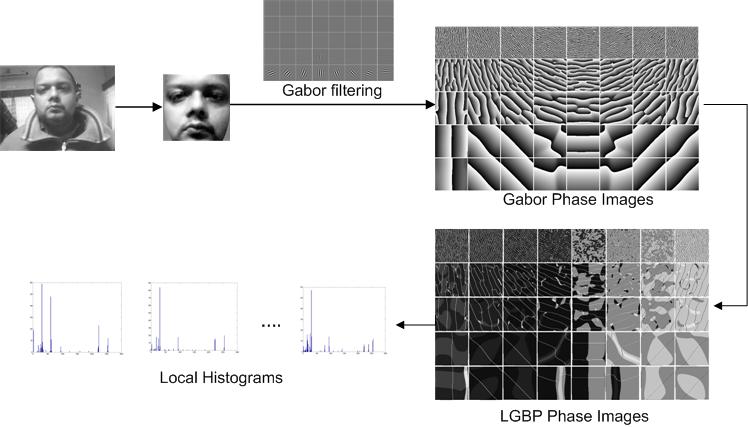
Because existing face recognition systems lack required accuracy when viewpoint, illumination, expression, occlusion, accessories and so on vary considerably, continued research in this field of biometrics is a challenging objective. It is widely accepted that local features in face images are more robust against such distortions and a spatial-frequency analysis is often more desirable to extract such features. Having good characteristics of space-frequency localization, wavelet analysis is the right choice for this purpose. Among various wavelet bases Gabor functions provide optimized resolution in both spatial and frequency domains. However, only the magnitudes of the Gabor coefficients are used as features for face recognition in most previous works, while the Gabor phases are deemed useless and ignored. But recently researchers are finding impressive results using Gabor phase based feature representations. At the earlier part of this project, we study the characteristics of the phase part of the Gabor wavelet by investigating on 70 different Gabor phase based feature extraction techniques for face recognition. Later, based on the observation, we propose a novel face recognition system using the discriminating capability of the basic 40 Gabor filters. Lastly, we propose two online systems for face verification and identification based on local and global threshold of the similarity measure. Experimental results show that, among the 40 basic Gabor-phase based feature representations, filter responses acquired from larger scales show higher discriminating ability for face recognition. Moreover, our proposed weighted vote based face recognition system shows high accuracy of 98.3% for 1000 subjects for a combination of the FERET, Indian and in-house databases on all three different similarity measures, outperforming the recognition accuracy 83.2% of conventional Gabor phase representation. Finally, the proposed face authentication method based on the 40 basic Gabor phase feature representation and the summation of the 40 basic Gabor phase feature representation show promising results, for images taken under unconstrained pose, illumination and expression changes. As a whole, this project studies different aspects of Gabor wavelet based human face recognition and proposes some novel methods for improved face classification.
A Navigational Aid System For Visually Impaired People

The project is an endeavor towards finding a solution to a navigational aid system that can guide a visually impaired people. The main challenge faced during this work is to design a system that can serve the purpose of both object detection and recognition and their distance calculation simultaneously. Microsoft Kinect helped us out as it has the facility to provide both RGB and DEPTH images through its stereo vision and IR camera. With the help of Kinect as the core input device and OpenCV Haar classifier for detection and recognition of objects, we are successful to build a prototype application that is trained to recognize objects and human faces in real time and also inform the user regarding object location in terms of direction and footsteps using speech synthesizer. More work is going on this project regarding improving performance in uncontrolled environment and adding more objects to recognize.
Leaf Shape Identification Based Plant Biometrics
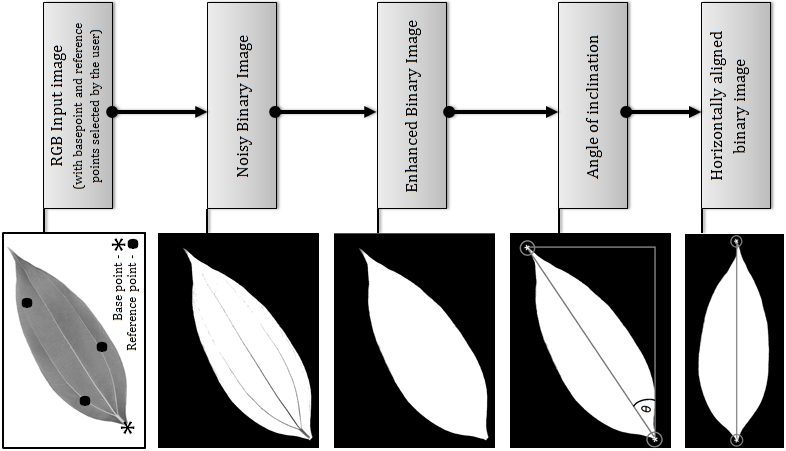
This paper presents a simple and computationally efficient
method for plant species recognition using leaf image. This
method works only for the plants with broad flat leaves
which are more or less two dimensional in nature. The method
consists of five major parts.
First, images of leaf are acquired with digital camera or
scanners. Then the user selects the base point of the leaf
and a few reference points on the leaf blades. Based on
these points the leaf shape is extracted from the background
and a binary image is produced. After that the leaf is
aligned horizontally with its base point on the left of the
image. Then several morphological features, such as
eccentricity, area, perimeter, major axis, minor axis,
equivalent diameter, convex area and extent, are extracted.
A unique set of features are extracted from the leaves by
slicing across the major axis and parallel to the minor
axis. Then the feature pointes are normalized by taking the
ratio of the slice lengths and leaf lengths (major axis).
These features are used as inputs to the probabilistic
neural network. The network was trained with 1200 simple
leaves from 30 plant species. The proposed method has been
tested using 10-fold cross-validation technique and the
system's average recognition accuracy is 91.41%.
Dual Iris Based Human Identification System
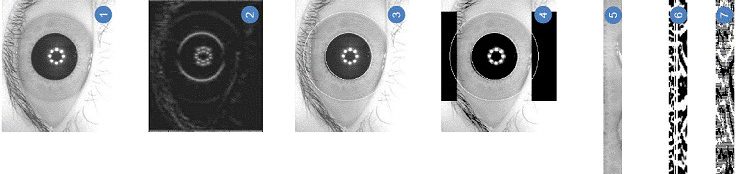
This system uses the distinctive human iris patterns to successfully identify authorized individuals. It detects the iris region from the eye image and then isolates the region and extracts useful features from it. It divides the selected iris region into pixels following a preset radial and angular and then maps the circular region into rectangular polar coordinate according to the resolutions. This polar image is then convolved with 1D log Gabor filter and phase of the response is quantized to four levels to generate the binary iris template and its corresponding mask. The Hamming distance between two iris templates is computed to find out if the templates are generated from the same iris or not. The conventional systems measure the Hamming Distance using iris images from a single eye. However, the proposed system takes images from both eyes simultaneously for comparison process which shows an increased accuracy and performance by eliminating the false acceptance (acceptance of intruders) and minimizing the false rejection (rejection of authorized personnel).